

- juillet 1, 2025
- Equipe journal IT
- 0
Vous êtes-vous déjà demandé si une intelligence artificielle pouvait comprendre non seulement vos mots, mais aussi vos images, vos sons et même vos vidéos, le tout en même temps ? C’est une question fascinante, n’est-ce pas ? La vérité est que, jusqu’à récemment, cela relevait presque de la science-fiction. Nombreux sont ceux qui se sentent perdus face à la vitesse incroyable des avancées en IA. On entend parler de ChatGPT, de Claude, et maintenant de Gemini. Comment s’y retrouver dans ce flot d’informations ? Et surtout, comment ces outils peuvent-ils vraiment vous aider au quotidien, que ce soit pour le travail, les études ou la créativité ?
Cet article est là pour éclaircir le mystère. Nous allons explorer ensemble Google Gemini, une innovation majeure conçue pour unifier ces différentes formes d’information. Vous découvrirez ses capacités uniques, comment il se positionne face à la concurrence et comment il peut transformer votre manière d’interagir avec la technologie. Préparez-vous à démystifier cette IA de nouvelle génération et à comprendre son potentiel immense.
Table de matières
ToggleOrigine et évolution des versions de Google Gemini
L’IA de Google a une histoire riche. Avant Gemini, il y avait les modèles PaLM. Ces modèles étaient déjà très performants en matière de texte. Mais Google voulait aller plus loin.
C’est ainsi qu’est né Gemini 1, fin 2023. Cette première version a marqué un tournant. Elle a apporté des capacités multimodales. Cela signifie qu’elle pouvait travailler avec du texte, mais aussi des images.
Puis, Gemini 1.5 a fait une entrée remarquée. Sa grande nouveauté est sa fenêtre de contexte d’un million de jetons. Pour vous donner une idée, cela représente environ 1 500 pages de texte. Imaginez pouvoir analyser un roman entier en une seule fois ! Google a ensuite introduit Gemini 1.5 Flash, optimisé pour la rapidité et l’efficacité.
Les versions récentes, Gemini 2.0 Flash et 2.5 Pro, poussent encore les limites. Gemini 2.5 Pro se distingue par son raisonnement sophistiqué. Il est capable de “réfléchir” avant de répondre. Il excelle dans la compréhension multimodale complète. Cela inclut l’analyse de vidéos, d’audio et d’images, en plus du texte. Ces modèles sont disponibles via Google AI Studio et l’application Gemini.
La feuille de route de Google est ambitieuse. On parle déjà de Gemini 3. L’objectif est de continuer à étendre ses capacités. Gemini ne cesse d’évoluer pour devenir toujours plus intelligent et utile.
Fondations techniques et innovations clés
Comprendre ce qui se passe sous le capot de Gemini aide à saisir sa puissance. Il ne s’agit pas juste d’une simple boîte qui répond à vos questions. C’est une architecture complexe et innovante.
Large Language Models (LLMs) et architecture de Gemini
Au fond, Gemini est un Large Language Model (LLM). Cela veut dire qu’il a été entraîné sur d’énormes quantités de données. Des textes, du code, des images, des sons, des vidéos. Son architecture principale est celle des “Transformers”, inventée par Google en 2017. Cette architecture est très efficace. Elle permet à l’IA de comprendre les relations entre les mots, les idées, et les différentes formes de données. Gemini est conçu pour être “nativellement multimodal”. Il ne convertit pas une image en texte pour la comprendre. Il la comprend directement, avec le texte, l’audio, etc., en même temps.
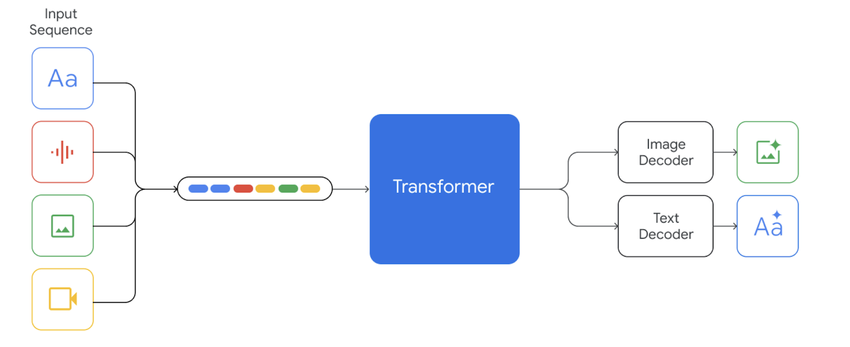
Schéma de l’architecture Gemini. Des séquences d’entrée multimodales (texte, audio, images, vidéo) sont converties en représentations unifiées et traitées par un transformateur central. Le modèle produit ensuite des sorties grâce à des décodeurs spécialisés, tels que le décodeur d’images et le décodeur de texte.
Fenêtre de contexte étendue jusqu’à 2M tokens
C’est une des plus grandes forces de Gemini, surtout avec les versions 1.5 Pro et 2.5 Pro. La fenêtre de contexte représente la quantité d’informations que l’IA peut traiter en une seule fois. Les anciens modèles étaient limités à quelques milliers de “tokens” (un token peut être un mot, un morceau de mot, ou une partie d’image/son). Gemini 1.5 Pro a cassé cette barrière avec 1 million de tokens. C’est comme pouvoir donner à l’IA un film entier ou un très gros livre. Des tests sont même en cours pour atteindre 2 millions de tokens ! Cette capacité permet à Gemini de ne rien “oublier” du début de votre conversation ou des documents que vous lui fournissez. Il peut ainsi faire des résumés longs, analyser de gros codes ou répondre à des questions sur des documents massifs sans perdre le fil.
Raisonnement avancé (“Deep Thinking”) et performances en benchmarks
Les dernières versions de Gemini, notamment la série 2.5, intègrent un mode de pensée profonde (Deep Thinking). Cela signifie que l’IA ne se contente pas de donner une réponse directe. Elle peut “réfléchir” en plusieurs étapes. Elle décompose le problème. Elle explore différentes hypothèses. Ce processus de raisonnement améliore grandement sa capacité à résoudre des tâches complexes. Par exemple, pour des problèmes de mathématiques avancées ou pour le débogage de code. Google teste même un mode “Deep Think” expérimental. Les performances de Gemini sont très bonnes sur les benchmarks, qui sont des tests standards pour comparer les IA. Il excelle sur des tests de compréhension multimodale et de raisonnement logique.
Recherche en temps réel avec intégration Search
Une autre innovation clé est l’intégration de Gemini avec la recherche Google. Cela lui permet d’accéder à des informations en temps réel. Contrairement à d’autres IA qui ont une “date limite” pour leurs connaissances (leur date de dernière mise à jour d’entraînement), Gemini peut chercher sur le web. Il peut ainsi fournir des réponses actualisées et précises. Quand vous posez une question, Gemini peut décider d’utiliser l’outil de recherche Google. Il va chercher l’information, la traiter et vous la présenter. Il cite même ses sources, ce qui est très utile pour vérifier l’information. Cette fonction aide à réduire les “hallucinations” (quand l’IA invente des faits).
Fonctionnalités multimodales
Ce qui rend Gemini vraiment unique, c’est sa capacité à être multimodal. Il ne se limite pas au texte. Il comprend et génère du contenu sous diverses formes.
Génération de texte (rédaction, résumé, traduction)
D’abord, la génération de texte. Gemini excelle dans la rédaction créative. Il peut résumer des documents longs et complexes avec précision. Il traduit aussi des textes dans de nombreuses langues, tout en conservant le contexte et le ton. C’est un outil puissant pour la rédaction de rapports, la création de scripts ou la simplification d’informations.
Génération d’images avec Imagen et filigrane SynthID
Ensuite, la génération d’images. Grâce à l’intégration d’Imagen, les modèles de pointe de Google pour la génération d’images (comme Imagen 3 ou 4), Gemini peut transformer des descriptions textuelles détaillées en visuels impressionnants et photoréalistes. Il est possible de générer des images stylisées, des logos ou des illustrations. Google a également mis en place SynthID. C’est un filigrane numérique, invisible à l’œil nu. Il est incrusté directement dans les images générées par l’IA. Cela permet de vérifier l’origine d’une image et de distinguer le contenu créé par l’IA du contenu réel. C’est une avancée clé pour la transparence et l’éthique.
Analyse et compréhension de vidéo (jusqu’à 5 min)
Gemini peut également analyser et comprendre des vidéos. Vous pouvez lui soumettre une vidéo ou une partie de vidéo. Il peut la résumer, extraire des informations clés ou des moments spécifiques. Il peut aussi répondre à des questions précises sur son contenu. Par exemple, “Que se passe-t-il à la 30ème seconde ?” ou “Quels sont les points principaux de cette présentation ?”. Bien que ses capacités évoluent, Gemini peut actuellement traiter des séquences vidéo allant jusqu’à plusieurs minutes, souvent citées autour de 5 minutes pour des analyses complexes, permettant un aperçu rapide de contenus longs.
Entrée et sortie vocales naturelles (Gemini Live)
Enfin, l’entrée et la sortie vocales naturelles. Avec “Gemini Live”, les conversations avec l’IA deviennent incroyablement fluides. Vous pouvez parler à Gemini comme à une personne. Il vous répond avec une voix naturelle et expressive, grâce à des avancées en synthèse vocale (text-to-speech ou TTS). Plus besoin d’attendre la fin de la phrase : vous pouvez l’interrompre, poser des questions de suivi. C’est une interaction très intuitive et réactive, presque humaine, qui transforme l’expérience utilisateur.
Ces capacités multimodales ouvrent des horizons incroyables. Elles changent notre manière d’interagir avec la technologie et la création de contenu.
Codage avancé et assistance développeur
Pour les développeurs, Gemini est bien plus qu’un simple outil ; c’est un partenaire de programmation. Il révolutionne la façon de coder, de déboguer et d’optimiser les projets. C’est un véritable copilote intelligent.
Génération et explication de code
Gemini excelle dans la génération de code. Décrivez en langage naturel ce que vous souhaitez accomplir. Gemini peut alors écrire des fragments de code ou des fonctions entières pour vous. Il supporte une vaste gamme de langages : Python, Java, JavaScript, Go, C++, Ruby, et bien d’autres. Cette capacité accélère considérablement le démarrage de nouveaux projets ou l’ajout de fonctionnalités. De plus, Gemini peut expliquer des blocs de code complexes. Il décompose le code en langage clair. Il rend ainsi le code plus accessible, même pour les débutants.
Débogage et amélioration automatique
Le débogage est souvent une tâche fastidieuse. Gemini simplifie ce processus. Il peut identifier les erreurs dans votre code rapidement. Il ne se contente pas de les signaler. Il propose également des solutions concrètes pour les corriger. Mieux encore, il peut suggérer des améliorations. Il peut transformer un code inefficace en un code optimisé. Cela inclut la refactorisation pour une meilleure lisibilité ou des optimisations de performance. Il réduit ainsi le temps passé à la correction de bugs et augmente la qualité du code.
Le Gemini CLI (terminal IA) : intégration locale et recherche instantanée
Une innovation clé pour les développeurs est le Gemini CLI (Command Line Interface). C’est un outil qui intègre la puissance de Gemini directement dans votre terminal. Cela signifie que vous pouvez interagir avec Gemini sans quitter votre environnement de développement. Vous pouvez lui demander de générer du code, de vous aider à déboguer un script ou même de chercher des informations techniques en temps réel.
Cette intégration locale est un atout majeur. Le Gemini CLI peut interagir avec vos fichiers de projet. Il peut lire du code, proposer des modifications ou même exécuter des commandes. C’est un assistant qui comprend le contexte de votre travail. De plus, sa capacité de recherche instantanée vous donne accès à des informations à jour. Vous n’avez plus besoin de quitter votre terminal pour chercher de la documentation ou des solutions en ligne. C’est un gain de temps et de productivité considérable. Gemini Code Assist, propulsé par Gemini, est aussi intégré dans les IDE populaires comme VS Code et JetBrains, offrant des complétions de code intelligentes et des suggestions en contexte.
Ces fonctionnalités avancées positionnent Gemini comme un outil indispensable pour tout développeur. Il permet de coder plus vite, plus intelligemment et avec moins d’erreurs.
Conclusion
Google Gemini est bien plus qu’une IA : c’est une révolution multimodale. Capable de comprendre et de générer texte, images, audio et vidéo, il redéfinit nos interactions numériques. Sa puissance de raisonnement et ses outils de codage avancés en font un leader.
Intégré au cœur de Google Workspace, Search et l’application Gemini, il est un assistant omniprésent. Des défis éthiques et réglementaires subsistent, mais Google s’engage pour une IA responsable. L’avenir de Gemini promet une intelligence toujours plus intuitive et utile, transformant notre productivité et notre créativité au quotidien.
FAQ
Comment utiliser Google Gemini pour la création de contenu ?
Gemini peut générer des idées de sujets, rédiger des brouillons de texte pour des articles, des courriels ou des scripts, et résumer de longs documents. Il est aussi capable de créer des images à partir de descriptions textuelles. Pour l’utiliser, il suffit de saisir les requêtes ou d’importer des fichiers pour obtenir de l’aide pour structurer et enrichir le contenu.
Google Gemini est-il gratuit et comment y accéder ?
Une version de base de Google Gemini est accessible gratuitement via l’application web (gemini.google.com) et l’application mobile Gemini. Pour accéder à des capacités plus avancées, comme une fenêtre de contexte étendue ou la génération vidéo, des abonnements payants tels que Google One AI Premium (incluant Gemini Advanced) sont disponibles. L’accès se fait simplement en se connectant avec un compte Google personnel.
Comment intégrer Google Gemini dans mon flux de travail ?
Gemini s’intègre directement dans les applications Google Workspace comme Gmail, Docs, Sheets et Slides, où il assiste à la rédaction ou à l’analyse. Pour les développeurs, le Gemini CLI (interface en ligne de commande) et l’API Gemini permettent d’incorporer ses fonctions de codage et de génération de contenu dans des applications ou des scripts personnalisés, automatisant ainsi des tâches complexes.
Google Gemini peut-il générer des images ou des vidéos ?
Oui, Gemini peut générer des images grâce à l’intégration des modèles Imagen, permettant la création de visuels détaillés à partir de descriptions textuelles. Quant à la génération de vidéos, des capacités émergentes comme Veo sont en cours de déploiement, offrant la possibilité de créer de courtes séquences vidéo à partir de requêtes textuelles. Ces fonctionnalités avancées sont généralement disponibles via les offres Gemini Advanced.
Comment Google Gemini utilise-t-il les données de l'utilisateur ?
Google utilise les données des requêtes et des interactions pour fournir, améliorer et développer ses services, y compris les technologies d’apprentissage automatique. Cela contribue également à renforcer la sécurité de Gemini. Google s’engage à protéger la vie privée des utilisateurs, en déconnectant certaines données des comptes et en appliquant des principes d’IA responsable pour la révision humaine et la conformité aux politiques de confidentialité.