
- juillet 10, 2025
- Equipe journal IT
- 0
Votre build met-il plus de temps à finir que votre café ne met à refroidir ? Cette simple question résume la pression quotidienne des équipes de développement : dépendances tentaculaires, livraisons continues qui s’enrayent et correctifs qui se propagent moins vite que les bugs. Quand le dépôt devient un goulot d’étranglement, le choix entre monorepo et polyrepo n’est plus un détail technique, c’est une décision stratégique.
Dans les projets modernes, la structure du dépôt agit comme une charpente invisible. Elle détermine la scalabilité de la base de code, la fluidité de la collaboration et la vitesse de mise en production. Mal pensée, elle gonfle les coûts, ralentit les releases et mine la motivation des développeurs.
Cet article vous guidera pas à pas. Vous allez découvrir les forces et faiblesses réelles des monorepos et des polyrepos, les critères pratiques pour trancher ou combiner ces approches, ainsi que les outils capables de maintenir la vélocité lorsque votre codebase grandit. L’objectif : rendre vos builds aussi rapides qu’un espresso corsé.
Table de matières
ToggleMonorepos : Code centralisé pour plusieurs projets
Définition et principe de fonctionnement
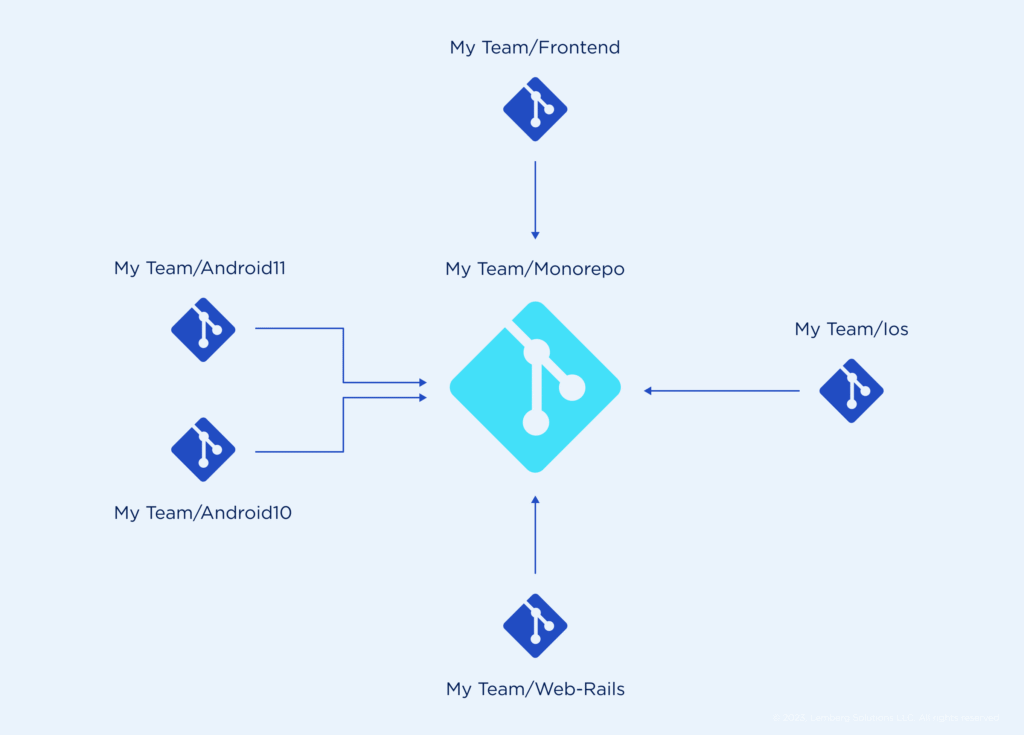
Un monorepo est un dépôt unique qui regroupe plusieurs projets indépendants. On parle aussi de dépôt monolithique. Tout le code partage l’historique Git, la configuration et les mêmes workflows CI/CD.
Chaque dossier représente un service, une application ou une bibliothèque commune. Les commits peuvent modifier plusieurs modules sans changer de dépôt, ce qui réduit la friction entre équipes. Des outils comme Bazel, Nx ou Turborepo gèrent les builds incrémentaux et exploitent un cache distribué pour maintenir des temps de compilation rapides, même en 2025.

Cas d’usage typiques
- Tech giants : Google et Meta pilotent des millions de fichiers dans un monorepo pour assurer cohérence et réutilisation de code.
- Produits centrés : une seule équipe peut refactoriser l’ensemble du produit sans jongler entre plusieurs dépôts.
- Design system : les composants UI, la documentation et les tests restent toujours en phase avec les applications clientes.
- Microservices couplés : quand les services évoluent ensemble, un correctif global se fait en une seule pull-request et un pipeline unifié.
Les avantages des monorepos
Partage de code et factorisation des dépendances
Centraliser tout le code réduit les duplications : les bibliothèques communes vivent dans un seul dossier, accessibles à chaque service. Les versions restent synchronisées, les correctifs critiques ne se perdent plus dans la nature.
Cette visibilité globale encourage la réutilisation. Un composant React ou une fonction d’authentification devient un point unique de vérité, supprimant les « copier-coller » risqués et les écarts de comportement entre projets.
Réalisation de changements transverses plus facilement
Un monorepo permet des commits atomiques : vous corrigez une API, mettez à jour tous les services dans la même PR, et vos tests s’exécutent d’un bloc. Plus besoin de coordonner dix dépôts pour un simple renommage.
Les outils modernes (Nx, Bazel, Turborepo) calculent quels projets sont « affectés » et ne reconstruisent que ceux-là. Les refactors globaux se propagent donc vite, sans faire exploser le temps de build.
Flux de travail unifiés et cohérents
Avec un seul pipeline CI/CD, les règles de lint, les tests et les politiques de sécurité s’appliquent partout de façon identique. Les équipes parlent le même langage et évitent les « ça marche chez moi ».
Le cache distant et les builds incrémentaux raccourcissent les boucles de feedback ; les déploiements deviennent prévisibles, même sur des bases de code gigantesques. Résultat : plus de vélocité, moins de surprises en production.
Les défis des monorepos
Complexité des pipelines CI/CD
Dans un monorepo, le moindre commit peut déclencher la compilation d’une partie massive du code. Les pipelines explosent et les temps de feedback s’allongent. Les équipes doivent investir dans des règles d’impact analysis, des caches distribués et une orchestration fine pour garder des builds rapides. Sans ces optimisations, les tests tournent plus longtemps que la fonctionnalité n’a mis à être codée.
Risques de conflits de dépendances
Partager un seul fichier package.json ou pom.xml simplifie la mise à jour… jusqu’à ce qu’une lib majeure passe en version breaking. Les services qui n’évoluent pas au même rythme se retrouvent coincés, et les devs bricolent des résolutions de versions locales qui divergent. Résultat : un « dépendency hell » qui bloque la livraison et génère des régressions sournoises.
Problèmes de performance et de scalabilité des outils
Un dépôt de plusieurs gigaoctets ralentit les clones, l’indexation des IDE et même certaines commandes Git. Les builds incrémentaux règlent une partie du problème, mais ils exigent des outils comme Bazel ou Nx et une configuration pointue. Sans une architecture modulaire stricte, la base de code devient si grande qu’elle dépasse la capacité mémoire des agents CI ou des postes de dev distants.
Polyrepos : Code distribué pour des services indépendants
Définition et principe de fonctionnement
Un polyrepo (ou multi-repo) consiste à placer chaque projet frontend, API, librairie partagée, microservice dans son propre dépôt Git. Chaque repository possède son historique, sa configuration CI/CD et ses droits d’accès. Cette séparation offre une grande souplesse : les équipes peuvent choisir leur stack, versionner à leur rythme et publier quand elles le souhaitent .
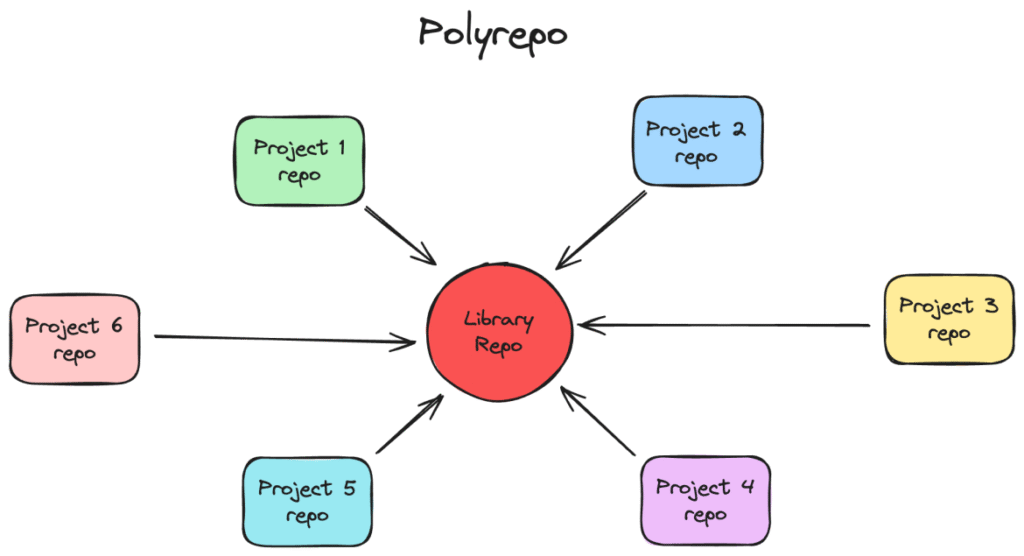

Cas d’usage typiques
- Architecture microservices à haute autonomie. Netflix héberge plus de 1 000 services dans des dépôts distincts ; chaque équipe déploie sans attendre les autres. Produits multi-plateformes. Vous séparez web, mobile et backend pour éviter qu’une mise à jour d’iOS ne casse le build Android.
- Équipes distribuées ou externes. Un vendor tiers peut contribuer à un seul repo sans accéder au reste du code, simplifiant la gouvernance et la conformité.
Les avantages des polyrepos
Déploiements indépendants et cycles de vie autonomes
Un dépôt par service signifie un pipeline par service. Chaque équipe décide quand publier, sans coordination globalisée. Les builds sont plus courts et les releases sortent dès que les tests passent, ce qui augmente l’agilité des micro-services.
Impacts plus limités en cas de changements
Un échec dans le dépôt A ne bloque pas la production du dépôt B. Les pipelines étant isolés, le « blast radius » d’un bug reste contenu, et vos week-ends demeurent tranquilles. Cette séparation réduit aussi le risque de régressions croisées lors des mises à jour.
Autonomie renforcée des équipes
Dans un polyrepo, chaque équipe choisit sa stack, fixe son rythme de versionnement et gère ses droits d’accès au plus fin. Résultat : plus de flexibilité, une gouvernance de sécurité simplifiée et une montée en compétence ciblée.
Les défis des polyrepos
Coordination des changements transverses
Dans un polyrepo, la moindre évolution globale nouvelle interface d’un service, changement de contrat API, mise à jour d’une dépendance critique doit se propager repo par repo. Chaque équipe ouvre sa propre pull-request, ajuste son pipeline et planifie son déploiement. Cette fragmentation multiplie les revues de code, rallonge les délais et crée parfois des goulots de validation qui bloquent la livraison en production.
Les risques augmentent encore si la « coupure » entre dépôts a été mal pensée : un changement transversal nécessitera alors de toucher plusieurs services à la fois, ce qui annule le gain d’autonomie initial.
Gestion des librairies partagées et duplication de code
Sans dépôt central, les librairies communes doivent être empaquetées puis publiées sur un registry privé (npm, Maven, NuGet…). Chaque service choisit quand l’adopter ; les versions dérivent vite, et un correctif de sécurité critique peut rester des semaines en attente de mise à jour. On parle alors de version drift.
Faute de process rigoureux, certains développeurs préfèrent copier-coller du code pour aller plus vite, générant des duplications et un « shadow fork » de la librairie originale qu’il faudra maintenir dans le temps.
Les approches hybrides et les outils de convergence
Présentation de Nx et Turborepo
Nx 21 cible les très grands monorepos : exécution « affected », cache distants (Nx Replay), et parallélisation avec Nx Agents. Tout cela s’appuie désormais sur un cœur ré-écrit en Rust pour accélérer chaque commande.
Turborepo 2.5 mise sur la simplicité : configuration JSONC commentable, tâches sidecar qui démarrent ensemble, et cache distant gratuit chez Vercel ou auto-hébergé. Les versions 2.x ont aussi introduit le filtrage intelligent des paquets impactés et un mode watch avec cache incrémental.
Comment ces outils fluidifient la gestion d’un monorepo géant
- Build incrémental + cache distribué : Nx Replay et Turborepo Remote Cache évitent de recompiler le code inchangé, même en CI. Les builds passent de minutes à secondes.
- Détection fine des changements : les graphes affected (Nx) et intelligent affected filters (Turborepo 2.2+) déclenchent seulement les tests utiles.
- Exécution parallèle : Nx Agents distribue les tâches sur plusieurs runners ; Turborepo gère les dépendances et relance seulement ce qui a échoué.
- Observabilité prête à l’emploi : matrices de durée, suivi des hits/miss cache et OpenAPI pour les caches Turborepo facilitent le tuning de la perf.
Bonnes pratiques pour exploiter une approche hybride
- Monorepo pour le socle commun : placez vos librairies partagées, design-system et scripts de build dans Nx ou Turborepo ; gardez les micro-services critiques dans leurs dépôts dédiés.
- Automatisez la synchronisation : créez un pipeline qui publie les paquets du monorepo vers un registry privé ; chaque polyrepo consomme la version pinée.
- Versionnez par release indépendante : utilisez Nx Release ou turbo prune pour générer des artefacts minces et isoler les cycles de vie.
- Définissez des frontières claires : exploitez les règles module-boundary (Nx) ou boundaries RFC (Turborepo 2.3) pour empêcher les importations circulaires.
- Mesurez, puis scindez : quand le dossier « apps » dépasse le million de lignes, migrez les parties qui changent le plus vers des polyrepos autonomes ; le reste reste centralisé pour la cohérence.
Une stratégie hybride garde la cohérence là où elle compte et la liberté là où c’est vital.
Choisir la bonne stratégie : monorepo ou polyrepo ?
Les facteurs clés à évaluer
- Taille de l’organisation – Plus l’équipe est grande, plus la coordination devient coûteuse ; un monorepo simplifie le partage mais requiert des outils solides.
- Nombre et nature des projets – Projets très couplés ? Centralisez. Services à cycles de vie distincts ? Séparez.
- Culture d’équipe – Une culture DevOps unifiée profite d’un dépôt unique ; des squads autonomes préfèrent plusieurs repos.
Maturité du tooling – Nx, Bazel ou Turborepo réduisent le « pain » d’un gros monorepo ; sans eux, les builds explosent. - Conformité & sécurité – Les polyrepos offrent un contrôle d’accès granulaire quand la réglementation l’impose.
Tableau comparatif synthétique
| Critère | Monorepo | Polyrepo |
|---|---|---|
| Build & CI | Cache et build incrémental indispensables, sinon pipelines lents. | Pipelines courts et ciblés. |
| Partage de code | Facile ; une seule source de vérité. | Packages publiés, risque de dérive de versions. |
| Cohérence tech | Règles et lint communs, updates atomiques. | Standards variables selon les dépôts. |
| Autonomie des équipes | Plus faible, coordination centrale nécessaire. | Haute, déploiements indépendants. |
| Contrôle d’accès | Global, plus complexe à restreindre. | Granulaire par dépôt. |
| Scalabilité organisationnelle | Exige un outillage robuste pour rester rapide. | Risque de duplications, mais croissance linéaire. |
Recommandations finales
- Start-up < 50 devs, produit intégré : adoptez un monorepo avec Nx ou Turborepo pour garder la vélocité et éviter le “not my repo syndrome”.
- Scale-up aux équipes multiples : hybridez ! Placez vos librairies communes dans un monorepo et laissez chaque micro-service critique vivre dans son polyrepo.
- Entreprise réglementée ou multi-produits : privilégiez le polyrepo pour isoler les risques, puis automatisez la publication des composants partagés afin de limiter les duplications.
À retenir
Adaptez votre structure de dépôt à la taille de l’équipe, au couplage du code et aux contraintes de conformité : choisir (ou ajuster) judicieusement entre monorepo, polyrepo ou approche hybride vous fera économiser des semaines de développement et des milliers d’euros de coûts cloud.
FAQ
Le choix dépend de la taille de l’équipe, du degré de couplage entre projets et du besoin d’autonomie. Un monorepo est pratique si les services partagent beaucoup de code ou évoluent ensemble. Plusieurs dépôts sont préférables si chaque service doit être versionné et déployé séparément, ou si des équipes différentes travaillent de façon indépendante
Pour une startup, un monorepo simplifie la configuration initiale : un seul dépôt à gérer, des outils communs et des mises à jour partagées plus faciles. L’inconvénient principal est qu’en grandissant, la base de code peut devenir lourde à maintenir et allonger les temps de build si elle n’est pas optimisée avec du cache ou des builds ciblés.
Un monorepo centralise les pipelines et permet de lancer tous les tests ensemble, ce qui garantit la cohérence. Mais cela peut alourdir les workflows si tout est reconstruit à chaque changement. Il est donc essentiel d’utiliser des outils de build incrémental (comme Nx, Bazel ou Turborepo) pour limiter la complexité et accélérer les déploiements.
Le code partagé doit être publié sous forme de packages versionnés (par exemple sur un registre privé npm, Maven, NuGet). Chaque service consomme ces packages comme des dépendances. Il faut documenter clairement les versions et automatiser la mise à jour pour éviter les écarts entre dépôts et les duplications de code.
Des solutions comme Nx, Turborepo, Bazel ou Lage facilitent la gestion des monorepos. Elles proposent le cache de build, l’analyse des changements affectés, l’exécution parallèle et des règles pour structurer les projets. Ces outils aident à conserver de bonnes performances même avec une base de code importante.